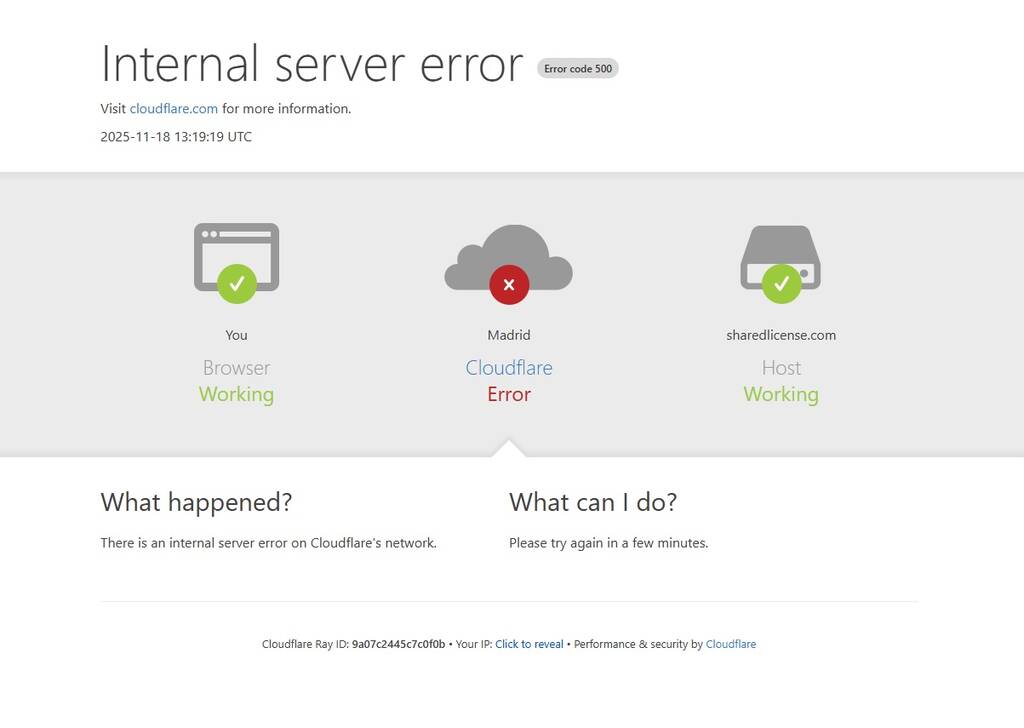
La red global de Cloudflare ha experimentado este martes 18 de noviembre de 2025 una interrupción masiva que ha degradado servicios en todo el mundo. El problema, que comenzó alrededor de las 11:48 UTC, provocó una cascada de fallos en plataformas populares como X (Twitter), ChatGPT de OpenAI, Spotify y Canva, entre muchas otras, ya que todo servicio que utilice esta red no funcionará mientras el servicio esté caído. Los usuarios están encontrando predominantemente con errores 500 y mensajes de "Internal server error" al intentar acceder a estos servicios.
Cloudflare identificó la causa raíz y comenzó a implementar una solución alrededor de las 13:09 UTC, y para las 13:13 UTC reportaba que servicios críticos como Cloudflare Access y WARP se estaban recuperando. A pesar de la recuperación, los clientes podían experimentar tasas de error más altas de lo normal mientras se completaban los esfuerzos de remediación.
La cronología del incidente, según las actualizaciones oficiales de Cloudflare muestra que a las 12:21 UTC se observaron servicios recuperándose, pero persistían tasas de error elevadas. A las 13:04 UTC, como medida correctiva local, se desactivó el acceso WARP en Londres para ayudar a la remediación, lo que impidió a los usuarios de esa zona conectarse a internet a través de esta herramienta.
La caída de Cloudflare, al ser un pilar de la infraestructura de internet, tuvo un efecto dominó en una gran variedad de servicios. La ironía de que Downdetector, el sitio web que monitoriza el estado de otros, también cayera temporalmente, no pasó desapercibida.
Entre los servicios y plataformas afectados se encontraron redes sociales y comunicación como la plataforma X (antes Twitter), que mostró a los usuarios "Internal server error". Servicios de inteligencia artificial como OpenAI, incluyendo su servicio ChatGPT, experimentaron interrupciones que coincidían en el tiempo con el problema de Cloudflare. Plataformas de entretenimiento y diseño como Spotify, Canva y la plataforma de videojuegos League of Legends también se vieron afectados, al igual que sitios de seguimiento como Downdetector y StatusGator.
Técnicamente, el fallo se manifestó para los usuarios finales como errores HTTP 500, indicando un problema en los servidores de Cloudflare y no en los dispositivos de los usuarios. La API y el Dashboard de Cloudflare también fallaron, limitando el acceso a los controles de gestión para sus clientes.
Cloudflare mantuvo un canal de comunicación constante a través de su página de estado, emitiendo actualizaciones en intervalos regulares. A las 13:13 UTC confirmaron: "Hemos realizado cambios que han permitido que Cloudflare Access y WARP se recuperen. Los niveles de error para los usuarios de Access y WARP han vuelto a las tasas previas al incidente. Hemos reactivado el acceso WARP en Londres".
El incidente demuestra la profunda integración de Cloudflare en la estructura de internet y cómo un problema técnico en una sola compañía puede afectar a millones de usuarios en plataformas cotidianas y diversas. Este evento se produce en un contexto de recientes interrupciones en otros grandes proveedores de infraestructura cloud como Amazon Web Services (AWS) y Microsoft Azure, que también causaron disrupciones generalizadas.

















")

















Agregar comentario